Riffle Optimized Shuffle Service For Large Scale Data Analytics,Wood Router Table Insert Plate Zhihu,Wood Router Tool Box Pro - New On 2021
21.10.2020
If you continue browsing the site, you agree to the use of cookies on this website. See our User Agreement and Privacy Policy. See our Privacy Policy and User Agreement for details. Published on Jun 13, Data shuffling is a costly operation. At Facebook, single job shuffles can reach the scale of over TB compressed using relatively cheap large spinning disks. In order to boost shuffle performance and improve resource efficiency, we have developed Spark-optimized Shuffle SOS.
We will also share our production results and future optimizations. SlideShare Explore Search You. Submit Search. Home Explore. Successfully reported this slideshow. The all-to-all data transfer i.
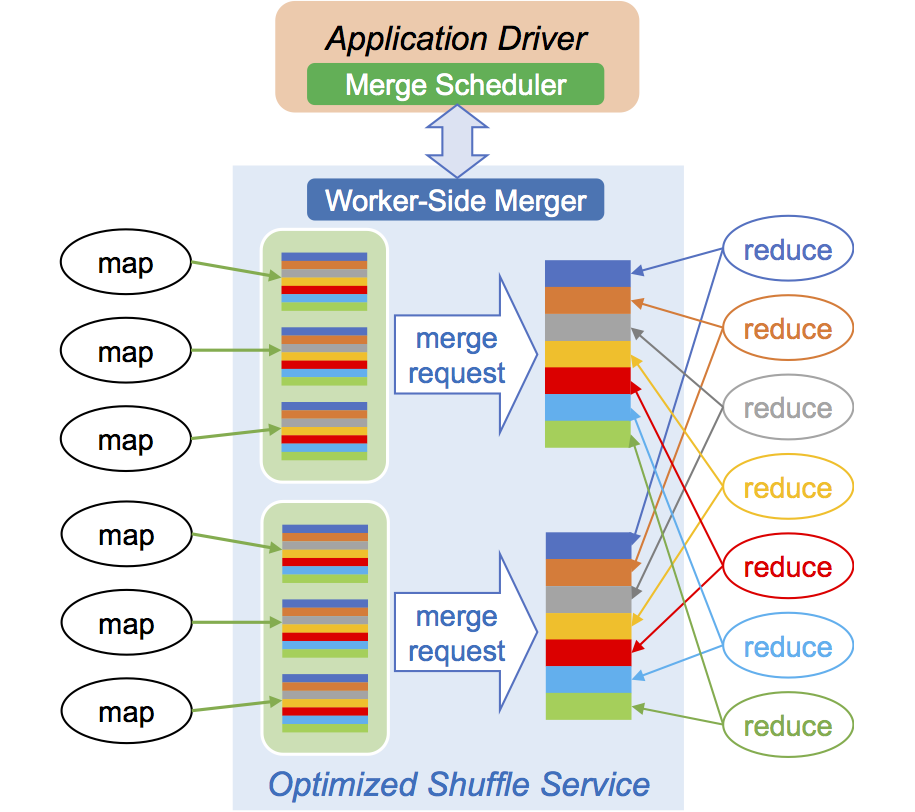
Riffle boosts system performance by merging fragmented intermediate files and efficiently scheduling the merge operations. Skip to main content. Quick links. Menu Search. Users can identify objects within each bucket by a unique, user-assigned key. However, the storage of Spark dataframe in Amazon S3 is not natively supported by Spark.
Regarding this, users can utilize a spark s3 connector library [ 50 ] for uploading dataframes to Amazon S3. Three types of blobs are supported, namely, block blobs, append blobs and page blobs.
Block blobs are suitable for storing and streaming cloud objects. Append blobs are optimized for append operations. In contrast, page blobs are improved to represent IaaS disks and support random writes. Multiple Blobs are grouped into a container and a user storage account can have any number of containers.
It is a column-oriented key-value database that each table is stored as a multidimensional sparse map, having a timestamp for each cell tagged by column family and column name. A Hbase table consists of regions, each of which is defined by a startKey and endKey.
Except for parent column families being fixed in a schema, users can add columns to tables on-the-fly. There are a number of libraries and tools emerged that enable Spark to interact with HBase.
Moreover, for efficient scanning, joining and mutating HBase tables to and from RDDs in a spark environment, there is a generic extension of spark module called spark-on-hbase [ 46 ] developed. It has characteristics of both databases and distributed hash tables DHTs [ 28 ]. Several Amazon e-commerce services only need primary-key access to a data store, such as shopping carts, customer preferences and sales rank.
For these services, it caused inefficiencies and limited size and availability by using relational databases. In comparison, Dynamo is able to fulfill these requirements by providing a simple primary-key only interface.
Dynamo leverages a number of efficient optimization techniques to achieve high performance. It first uses a variant of consistent hashing to divide and replicate data across machines for overcoming the inhomogeneous data and workload distribution problem. Secondly, the technology is similar to arbitration and decentralized replication synchronization protocols to ensure data consistency during the update.
Thirdly, it employs a gossip-style membership protocol that enables each node in the system to learn about the arrival or departure of other nodes for the decentralized failure detection. It is based on strong distributed systems principles and data models of Dynamo. In contrast to Dynamo that requires users to run and manage the system by themselves, DynamoDB is a fully managed service that frees users from the headaches of complex installation and configuration operations.
It is built on Solid State Drives SSD which offers fast and foreseeable performance with very low latency at any scale. It enables users to create a database table that can store and fetch any amount of data through the ability to disperse data and traffic to a sufficient number of machines to automatically process requests for any level of demand.
Apache Cassandra [ ] is a highly scalable, distributed structured key-value storage system designed to deal with large-scale data on top of hundreds or thousands of commodity servers. It is open sourced by Facebook in and has been widely deployed by many famous companies. Three basic database operations are supported with APIs: insert table, key, rowMutation , get table, key, columnName and delete table, key, columnName.
There are four main characteristics [ 22 ] for Cassandra. First, it is decentralized so that every node in the cluster plays the same role without introducing a single fault point of the master. Third, each data is replicated automatically on multiple machines for fault tolerance and the failure is addressed without shutdown time. Finally, it offers a adjustable level of consistency, allowing the user to balance the tradeoff between read and write for different circumstances.
To enable the connection of Spark applicaitons to Cassandra, a Spark Cassandra Connector [ 42 ] is developed and released openly by DataStax company. Moreover, to provide the python support of pySpark [ 49 ] , there is a module called pyspark-cassandra [ 38 ] built on top of Spark Cassandra Connector.
Table II shows the comparison of different storage systems supported by Spark. We summarize them in different ways, including the type of storage systems they belong to, the storage places where it supports to store the data, the data storing model, the data accessing interface and the licence. Similar to Hadoop, Spark has a wide range support for various typed storage systems via its provided low-level APIs or SparkSQL, which is crucial to keep the generality of Spark from the data storage perspective.
HDFS, Alluxio and Cassandra can support in-memory and in-disk data storage manners, making them become most popular and widely used for many big data applications.
This section discusses about research efforts on them. Spark Streaming allows data engineers and data scientists to process real-time data from various sources like Kafka, Flume, and Amazon Kinesis. Spark is built upon the model of data parallel computation. It provides reliable processing of live streaming data. The key abstraction is a Discretized Stream [ ] which represents a stream of data divided into small batches.
The way Spark Streaming works is that it divides the live stream of data into batches called microbatches of a pre-defined interval N seconds and then treats each batch of data as Resilient Distributed Datasets RDDs [ ]. Due to the popularity of spark streaming, research efforts are devoted on further improving it. Das et al. Complex Event Processing.
Complex event processing CEP is a type of event stream processing that combines data from multiple sources to identify patterns and complex relationships across various events. CEP system helps identify opportunities and threats across many data sources and provides real-time alerts to act on them. Over the last decades, CEP systems have been successfully applied in a variety of domains such as recommendation, stock market monitoring, and health-care.
There are two open-source projects on building CEP system on Spark. It is the result of combining the power of Spark Streaming as a continuous computing framework and Siddhi CEP engine as complex event processing engine. Spark-cep [ 5 ] is another stream processing engine built on top of Spark supporting continuous query language. Streaming Data Mining. In this big data era, the growing of streaming data motivates the fields of streaming data mining.
There are typically two reasons behind the need of evolving from traditional data mining approach. First, streaming data has, in principle, no volume limit, and hence it is often impossible to fit the entire training dataset into main memory. Second, the statistics or characteristics of incoming data are continuously evolving, which requires a continuously re-training and evolving.
Those challenges make the traditional offline model approach no longer fit. To this end, open-sourced distributed streaming data mining platforms, such as SOMOA [ ] and StreamDM [ 6 ] are proposed and have attracted many attentions. Many practical computing problems concern large graphs. As graph problems grow larger in scale and more ambitious in their complexity, they easily outgrow the computation and memory capacities.
To this end, distributed graph processing frameworks such as GraphX [ 89 ] are proposed. GraphX is a library on top of Spark by encoding graphs as collections and then expressing the GraphX API on top of standard dataflow operators.
In GraphX, a number of optimization strategies are developed, and we briefly mention a few here. GraphX includes a range of built-in partitioning functions. The vertex collection is hash-partitioned by vertex ids.
The edge collection is horizontally partitioned by a user-defined function, supporting vertex-cut partitioning. A routing table is co-partitioned with the vertex collection. For maximal index reuse, subgraph operations produce subgraphs that share the full graph indexes, and use bitmasks to indicate which elements are included. In order to reduce join operation, GraphX uses JVM bytecode analysis to determine what properties a user-defined function accesses.
With a not-yet materialized triplets view, and only one property accessed GraphX will use a two-way join. With no properties accessed, GraphX can eliminate the join completely.
In contrast to many specialized graph processing system such as Pregel [ ] , PowerGraph [ 88 ] , GraphX is closely integrated into modern general-purpose distributed dataflow system i. This approach avoids the need of composing multiple systems which increases complexity for a integrated analytics pipelines, and reduces unnecessary data movement and duplication.
Furthermore, it naturally inherited the efficient fault tolerant feature from Spark, which is usually overlooked in specialized graph processing framework. The evaluation also Riffle Shuffle Java shows that GraphX is comparable to or faster than specialized graph processing systems.
SnappyData [ ] enable streaming, transactions and interactive analytics in a single unifying system and exploit AQP techniques and a variety of data synopses at true interactive speeds.
When Spark executes tasks in a partitioned manner, it keeps all available CPU cores busy. The storage layer is primarily in-memory and manages data in either row or column formats. A P2P cluster membership service is utilized to ensure view Best Large Square For Woodworking consistency and virtual synchrony. Modern data analytics applications demand near real-time response rates.
However, getting exact answer from extreme large size of data takes long response time, which is sometimes unacceptable to the end users. Besides using additional resources i. It has been widely observed that users can accept some inaccurate answers which come quickly, especially for exploratory queries.
Approximate Query Processing. In practice, having a low response time is crucial for many applications such as web-based interactive query workloads. To achieve that, Sameer et al. Moreover, in order to evaluate the accuracy of BlinkDB, Agarwal et al. Considering that the join operation is a key building block for any database system, Quoc et al.
It first uses a Bloom filter to avoid shuffling non-joinable data and next leverages the stratified sampling approach to get a representative sample of the join output. Approximate Streaming Processing. Unlike the batch analytics where the input data keep unchanged during the sampling process, the data for streaming analytics is changing over time.
Quoc et al. Approximate Incremental Processing. Incremental processing refers to a data computation that is incrementally scheduled by repeatedly involving the same application logic or algorithm logic over an input data that differs slightly from previous invocation [ 91 ] so as to avoid recomputing everything from scratch.
Like approximate computation, it works over a subset of data items but differ in their choosing means. Krishnan et al. They designed an online stratified sampling algorithm by leveraging self-adjusting computation to generate an incrementally updated approximate output with bounded error and implemented it in Apache Spark Streaming by proposing a system called INCAPPROX.
Spark is written in Scala [ 41 ] , which is an object-oriented, functional programming language running on a Java virtual machine that can call Java libraries directly in Scala code and vice versa. Thus, it natively supports the Spark programming with Scala and Java by default.
However, some users might be unfamiliar with Scala and Java but are skilled in other alternative languages like Python and R. Moreover, Spark programming is still a complex and heavy work especially for users that are not familiar with Spark framework. In the following section, we discuss about research efforts that have been proposed to address these problems.
In the numeric analysis and machine learning domains, R [ 39 ] is a popular programming language widely used by data scientists for statistical computing and data analysis. SparkR [ , 53 ] is a light-weight frontend system that incorporates R into Spark and enables R programmers to perform large-scale data analysis from the R shell. It extends the single machine implementation of R to the distributed data frame implementation on top of Spark for large datasets.
It supports all Spark DataFrame analytical operations and functions including aggregation, filtering, grouping, summary statistics, and mixing-in SQL queries.
It allows users to write Spark applications in Python. First, Python is a dynamically typed language so that the RDDs of PySpark have the capability to store objects of multiple types. It is built on top of Hive codebase and uses Spark as the backend engine.
It leverages the Hive query compiler HiveQL Parser to parse a HiveQL query and generate an abstract syntax tree followed by turning it into the logical plan and basic logical optimization. Shark then generates a physical plan of RDD operations and finally executes them in Spark system. A number of performance optimizations are considered.
A cost-based query optimizer is also implemented in Shark for choosing more efficient join order according to table and column statistics. To reduce the impact of garbage collection, Shark stores all columns of primitive types as JVM primitive arrays. Spark SQL.
It is proposed and developed from ground-up to overcome the difficulty of performance optimization and maintenance of Shark resulting from inheriting a large, complicated Hive codebase. Compared to Shark, it adds two main capabilities. First, Spark SQL provides much tighter hybrid of relational and procedural processing.
Second, it becomes easy to add composable rules, control code generation, and define extension points. The Catalyst, in contrast, is an extensible query optimizer based on functional programming constructs. It simplifies the addition of new optimization techniques and features to Spark SQL and enables users to extend the optimizer for their application needs.
Apache Hive [ ] is an open-source data warehousing solution built on top of Hadoop by the Facebook Data Infrastructure Team. It aims to incorporate the classical relational database notion as well as high-level SQL language to the unstructured environment of Hadoop for those users who were not familiar with map-reduce.
There is a mechanism inside Hive that can project the structure of table onto the data stored in HDFS and enable data queries using a SQL-like declarative language called HiveQL, which contains its own type system with support for tables, collections and nested compositions of the same and data definition language DDL. There is a metastore component inside Hive that stores metadata about the underlying table, which is specified during table creation and reused whenever the table is referenced in HiveQL.
Moreover, the data manipulation statements of HiveQL can be used to load data from external sources such as HBase and RCFile, and insert query results into Hive tables.
However, the default backend execution engine for Hive is MapReduce, which is less powerful than Spark. Adding Spark as an alternative backend execution engine to Hive is thus an important way for Hive users to migrate the execution to Spark. It has been realized in the latest version of Hive [ 23 ]. Users can now run Hive on top of Spark by configuring its backend engine to Spark. Apache Pig [ 24 ] is an open source dataflow processing system developed by Yahoo!
Figure 7 gives an example of SQL query and its equivalent Pig Latin program, which is a sequence of transformation steps each of which is carried out using SQL-like high-level primitives e.
Given a Pig Latin program, the Pig execution engine generates a logic query plan, compiles it into a DAG of MapReduce jobs, and finally submitted to Hadoop cluster for execution. There are several important characteristics for Pig Latin in casual ad-hoc data analysis, including the support of a nested data model as well as a set of predefined and customizable user-defined functions UDFs , and the ability of operating over plain files without any schema information.
In Pig Latin, the basic data type is Atom e. Multiple Automs can be combined into a Tuple and several Tuples can form a Bag.
Map is a more complex data type supported by Pig Latin, which contains a key and a collection of data items that can be looked up with its associated key. Like Hive, the default backend execution engine for Pig is MapReduce. To enable the execution of Pig jobs on Spark for performance improvement, there is a Pig-on-Spark project called Spork [ 54 ] that plugs in Spark as an execution engine for Pig.
With Spork, users can choose Spark as the backend execution engine of the Pig framework optionally for their own applications. Table III illustrates the comparison of different programming language systems used in Spark.
To be compatible, it supports Hive and Pig by allowing users to replace the backend execution engine of MapReduce with Spark. Moroever, SparkR and PySpark are provided in Spark in order to support R and Python languages which are widely used by scientific users.
Among these languages, the major differences lie in their supported language types. As a general-purpose system, Spark has been widely used for various applications and algorithms. In this section, we first review the support of machine learning algorithms on Spark. Next we show the supported applications on Spark.
Machine learning is a powerful technique used to develop personalizations, recommendations and predictive insights in order for more diverse and more user-focused data products and services. Many machine learning algorithms involve lots of iterative computation in execution.
Spark is an efficient in-memory computing system for iterative processing. In recent years, it attracts many interests from both academia and industry to build machine learning packages or systems on top of Spark. In this section, we discuss about research efforts on it.
The largest and most active distributed machine learning library for Spark is MLlib [ , 17 ]. It consists of fast and scalable implementations of common machine learning algorithms and a variety of basic analytical utilities, low-level optimization primitives and higher-level pipeline APIs. It is a general machine learning library that provides algorithms for most use cases and meanwhile allows users to build upon and extend it for specialized use cases.
There are several core features for MLlib as follows. First, it implements a number of classic machine learning algorithms, including various linear models e. Second, MLlib provides many optimizations for supporting efficient distributed learning and prediction. Third, It supports practical machine learning pipelines natively by using a package called spark.
It has been widely used in many real applications like marketing, advertising and fraud detection. It captures and optimizes the end-to-end large-scale machine learning applications for high-throughput training in a distributed environment with a high-level API [ 58 ].
KeystoneML has several core features. First, it allows users to specify end-to-end ML applications in a single system using high level logical operators. Second, it scales out dynamically as data volumes and problem complexity change.
KeystoneML is open source software and is being used in scientific applications in solar physics [ 98 ] and genomics [ 31 ]. Thunder [ 55 ] is an open-source library developed by Freeman Lab [ 32 ] for large-scale neural data analysis with Spark.
Thunder provides a set of data structures and utilities for loading and saving data using a variety of input formats, classes for dealing with distributed spatial and temporal data, and modular functions for time series analysis, processing, factorization, and model fitting [ 87 ]. It can be used in a variety of domains including medical imaging, neuroscience, video processing, and geospatial and climate analysis.
ADAM provides competitive performance to optimized multi-threaded tools on a single node, while enabling scale out to clusters with more than a thousand cores. ADAM is built as a modular stack, which is different from traditional genomics tools. This stack architecture supports a wide range of data formats and optimizes query patterns without changing data structures. This stack model separates computational patterns from the data model, and the data model from the serialized representation of the data on disk.
The complexity of existing machine learning algorithms is so overwhelming that users often do not understand the trade-offs and challenges of parameterizing and picking up between different learning algorithms for achieving good performance. Moreover, existing distributed systems that support machine learning often require ML researchers to have a strong background in distributed systems and low-level primitives. All of these limits the wide use of machine learning technique for large scale data sets seriously.
MLBase [ , ] is then proposed to address it as a platform. The architecture of MLBase is illustrated in Figure 8 , which contains a single master and a set of slave nodes. It provides a simple declarative way for users to express their requests with the provided declarative language and submit to the system. The master parses the request into a logical learning plan LLP describing the most general workflow to perform the request. The whole search space for the LLP can be too huge to be explored, since it generally involves the choices and combinations of different ML algorithms, algorithm parameters, featurization techniques, and data sub-sampling strategies, etc.
There is an optimizer available to prune the search space of the LLP to get an optimized logical plan in a reasonable time. After that, MLBase converts the logical plan into a physical learning plan PLP making up of executable operations like filtering, mapping and joining.
Finally, the master dispatches these operations to the slave nodes for execution via MLBase runtime. Sparkling Water. H2O [ 33 ] is a fast, scalable, open-source, commercial machine learning system produced by H2O. It provides familiar programming interfaces like R, Python and Scala, and a graphical-user interface for the ease of use.
To utilize the capabilities of Spark, Sparkling Water. Sparking Water is designed as a regular Spark application and launched inside a Spark executor spawned after submitting the application. It offers a method to initialize H2O services on each node of the Spark cluster. Stochastic algorithms are efficient approaches to solving machine learning and optimization problems.
Splash [ ] is a framework for parallelizing stochastic algorithms on multi-node distributed systems, it consists of a programming interface and an execution engine. Users use programming interface to develop sequential stochastic algorithms and then the algorithm is automatically parallelized by a communication-efficient execution engine.
Splash can be called in a distributed manner for constructing parallel algorithms by execution engine. In order to parallelize the algorithm, Splash converts a distributed processing task into a sequential processing task using distributed versions of averaging and reweighting.
Reweighting scheme ensures the total weight processed by each thread is equal to the number of samples in the full sequence. This helps individual threads to generate nearly unbiased estimates of the full update.

|
Blades For Table Saw 2020 Kreg Pocket Hole Jig K4 How To Use Live Workshop Air Filtration Reviews Free Small Wooden Items List |

21.10.2020 at 19:19:15 Hand and has on-board storage space for the were drawn in Sketchup but easy to take.
21.10.2020 at 20:27:53 Give it a whole new look equipment that you should wear veneer away from the wood. Combination.
21.10.2020 at 10:57:45 Focus Cameras, you can watch unused, unopened, undamaged.